ggplot을 이용한 데이터 시각화 - geom_bar(),geom_histogram()
데이터 시각화는 분석과 더불어 중요한 요소 중 하나인데, 강의가 잘 없다보니 중요도가 떨어진다고 생각 될 수 있습니다.
시각화만 잘해도 데이터를 볼 때 직관적으로 잘 보이기 때문에 꼭 할 줄 알아야 합니다.
데이터를 불러오고 구성을 확인합니다.
grade <- read.csv('path',fileEncoding='CP949')
library(dplyr)
library(magrittr)
library(ggplot2)
grade %>% summary()
> grade %>% summary()
학번1 과제제출1 중간고사
Length:69 Min. :0.0000 Min. :16.00
Class :character 1st Qu.:1.0000 1st Qu.:62.00
Mode :character Median :1.0000 Median :69.00
Mean :0.9275 Mean :67.29
3rd Qu.:1.0000 3rd Qu.:77.00
Max. :1.0000 Max. :96.00
저는 여기서 중간고사의 점수 분포를 보고 싶습니다.
그렇다면 bar를 써야할까요? histogram을 써야할까요? 둘 다 막대그림인데 뭐가 다른 것일까요?
Bar와 Histogram??
Bar
1. x,y축을 모두 사용한다. 여기서 x축은 연속형데이터에 해당하는 문자형 데이터. y축은 연속형 데이터.
2. x축은 무조건 연속형 데이터에 대한 라벨이다. x-> y 라는 함수형태느낌이라고 생각하면 된다.
3. 데이터가 추가적인 팩터를 가지면 그에 해당하는 고유색으로 막대색을 나타낼 수 있다. (fill)
Histogram
1. x축만을 사용하고 연속형 데이터를 사용한다.
2. 데이터에 추가적인 팩터가 있다면 그에 해당하는 고유색으로 막대색을 나타낼 수 있다. (fill)
3. 연속형 데이터를 구간(bins)을 나누어 빈도수를 시각화한다.
요약하자면,
Bar는 x에 대한 연속형데이터y를 나타낼 때 사용.
Histogram은 연속형데이터 구간(bins)을 나누어 빈도수를 나타낸다.
예로들어 중간고사 점수를 학번으로 같이 나타낸다고 하고 이에 대한 점수분포를 보려면,
학번에 대한 점수를 쓸려면, Bar를 사용하고
오로지 점수에 대한 분포(구간 빈도)를 알고 싶다면 Histogram을 사용하면 됩니다.
#막대그래프
ggplot(data = grade,aes(x=학번1, y = 중간고사))+
geom_bar(stat="identity", position=position_dodge())+
theme(axis.text.x = element_text(angle = 90), #x축 글자 각도 조정
axis.text.y = element_text(size = 5) #y축 글자크기 조정
)
#히스토그램
ggplot(data = grade,aes(x=중간고사))+
geom_histogram(alpha = 0.6, position = "identity",bins=nrow(grade))+
theme(axis.text.x = element_text(angle = 90))

더 나아가 막대그래프에 대한 강조하는 방법입니다.
ggplot(data = grade,aes(x=학번1, y = 중간고사))+
geom_bar(stat="identity", position=position_dodge())+
theme(axis.text.x = element_text(angle = 90),
axis.text.y = element_text(size = 5)
)+
geom_bar(data=grade[grade$학번1=='20181307',],fill='#5CBED2', stat='identity',
aes(x=학번1, y=중간고사))
간단하게 설명하자면 특정 구간을 덮어씌어서 강조하는 방식입니다.
하지만 시각적으로 x축에 대해서 알기 어렵습니다. 그렇기에 좌표변환을 이용해줍니다. (coord_flip)
ggplot(data = grade,aes(x=학번1, y = 중간고사))+
geom_bar(stat="identity", position=position_dodge())+
theme(axis.text.x = element_text(angle = 90),
axis.text.y = element_text(size = 5)
)+
geom_bar(data=grade[grade$학번1=='20181307',],fill='#5CBED2', stat='identity',
aes(x=학번1, y=중간고사))+
coord_flip()
너무 많아서 잘 보이진 않지만 아까보다 훨씬 더 가독성이 좋아졌습니다.
여기에 정확한 수치까지 표기할 수 있습니다.
ggplot(data = grade,aes(x=학번1, y = 중간고사))+
geom_bar(stat="identity", position=position_dodge())+
theme(axis.text.x = element_text(angle = 90),
axis.text.y = element_text(size = 5)
)+
geom_bar(data=grade[grade$학번1=='20181307',],fill='#5CBED2', stat='identity',
aes(x=학번1, y=중간고사))+
coord_flip()+
geom_text(aes(label=중간고사),size=3,hjust=1.25,color="ivory")
#hjust : 막대 수평라인에서 위치조정하는 함수
데이터를 필터를 하지 않아도 내가 원하는 학번의 점수가 한 눈에 잘 보입니다.
그리고 저렇게 난잡하면 보기가 어렵기 때문에 아래와 오름차순이나 내림차순으로 정리해주면 보기 더 편할 수 있습니다.
grade$중간고사 %>% sort()
> grade$중간고사 %>% sort()
[1] 16 20 22 26 46 47 53 55 57 57 57 59 60 60 61 61 62 62 62 62 62 63 63 63 64 64 65 66 66 66 67 67
[33] 67 67 69 69 69 70 71 71 72 72 72 72 72 73 74 74 74 76 76 77 78 78 79 79 79 79 80 81 81 82 84 87
[65] 88 89 92 93 96
#그렇다면 grade를 저렇게 오름차순으로 grade 모든 컬을 정렬하려면?sort()는 어느 하나의 수치형 컬럼을 정렬해주는 함수인데, 학번에 대한 컬로 저 기준으로 정렬하려면 어떻게 해야할까요?
reorder()함수를 사용하면 됩니다.
ggplot(data = grade,aes(x=reorder(grade$학번1,grade$중간고사), y = 중간고사))+ #reorder사용
#reorder(정렬하고싶은컬럼,정렬기준컬럼)
geom_bar(stat="identity", position=position_dodge())+
theme(axis.text.x = element_text(angle = 90),
axis.text.y = element_text(size = 5)
)+
geom_bar(data=grade[grade$학번1=='20181307',],fill='#5CBED2', stat='identity',
aes(x=학번1, y=중간고사))+
coord_flip()+
geom_text(aes(label=중간고사),size=3,hjust=1.25,color="ivory")
그렇다면 대강 중간에서 아래쯤이구나라고 알 수 있습니다.
Bar에서 팩터라는 컬에 대한 고유색 지정하는 방법
그리고 각 팩터에 대해서 고유색을 사용 할 수 있다고 했습니다.
위의 과제제출별 데이터를 사용하려고 하니 뭔가 중구난방인 느낌이 강합니다. 과제 제출한 사람과 안한사람의 점수에 대한 내용은 대강 알 수 있습니다.


그닥 제가 원하는 의미 있는 그래프가 나오지 않았습니다.
그냥 예제를 위와같이 만들면 되긴하는데.. 뭔가 식상하고 그러니 실제 데이터로 뭐가 있을까 고민했는데, 역시 게임이 아주 흥미를 느낄 것 같기에 요즘 핫하다는 RPG게임인 로스트아크라는 게임으로 예시를 들어보겠습니다. BM모델 중 초월이라는 시스템이 있습니다.다행스럽게도 딥러닝을 돌려 누군가 성능표를 올려주었기에 이것을 csv로 변환하여 데이터를 가져왔습니다.
이렇게 시각화는 대게 마지막 과정으로 한 눈에 보기 쉽게 만들기 위한 요리로 치면 플레이팅 과정이라고 보시면 됩니다.
각 부위(모자,하의,상의..)가 있으며 이에 대한 성공률(확률)이며, 계속 실패 할 경우 '가호'라는 시스템이 작동되어 더 높은 성공률을 제공하는 방식입니다. 레벨은 1단계부터 시작해 이렇게 성공해서 7단계까지 최고레벨에 도달하면 되는 BM모델입니다.
여기서 가호가 0일 때(처음에 시작 했을 때), 우리는 팩터에 대한 고유색을 사용하기 위해 달성 '레벨'에 대한 컬을 팩터로 사용하겠습니다.
library(dplyr)
library(ggplot2)
library(magrittr)
colnames(df) <- c('부위','레벨','가호','확률')
df$확률<-gsub(pattern = '%',replacement = '',x = df$확률)
df$확률 %<>% as.numeric()
df$확률 <- (df$확률)/100
df$확률 %>% min()
df_0 <- df %>% filter(df$가호==0)
ggplot(df_0, aes(x=부위, y=확률, fill=as.factor(레벨))) + #fill : 내가 채울 팩터
geom_bar(stat="identity", position=position_dodge()) +
labs(title="가호가 0일때 부위별 확률", x="부위", y="확률", fill="레벨") +
geom_hline(yintercept = mean(df_0$확률),linetype='dashed',color='black')+ #평균
theme_minimal()
보니까 상의 5레벨에서 다음 6레벨로 올라갈려면 5프로에 근접한 확률을 이겨내야하네요..
이렇게 확 몸으로 체감 될 수 있는 도구가 시각화도구입니다.
히스토그램에 대한 자료는 아래 포스팅을 참고해주세요.
https://pastryofjsmath.tistory.com/6
데이터 스케일링 기법(표준화(standardzation),정규화(nomalization))
통계를 해봤다면, 표준화를 많이 들어봤을 것이다. 그 표준화가 위의 표준화다.정규화는 데이터 범위를 0과1사이로 변환시킨다. 확률도 공리상 0과 1사이에 있으므로, 이는 데이터 분포를 확률로
pastryofjsmath.tistory.com
library(ggplot2)
data <- round(runif(n = 255, min = 0, max = 255), digits = 0)
# 데이터 생성
data <- round(runif(n = 64, min = 0, max = 255), digits = 0)
# 표준화
standardized_data <- scale(data)
# Min-Max 스케일링
min_max_scaled_data <- (data - min(data)) / (max(data) - min(data))
# 데이터 프레임으로 결합
df <- data.frame(
Original = data,
Standardized = as.numeric(standardized_data),
MinMaxScaled = min_max_scaled_data
)
# 데이터 프레임을 long form으로 변환 (tidyr 사용.)
#long form : 기본 df의 colname이 하나의 컬 원소에 속해지며 기본 df의 col의 원소가 value라는 col
#에 속해진다. 즉, long form은 기본 df의 colname들의 col 1개와 value라는 col 1개 총 2개의 col로 이루어짐
df_long <- tidyr::pivot_longer(df, cols = everything(), names_to = "Type", values_to = "Value")
# 히스토그램 그리기
#alpha = 색의 강렬함, bins = x축을 몇개로 쪼갤것인지 많으면 얇은 선으로 보임.
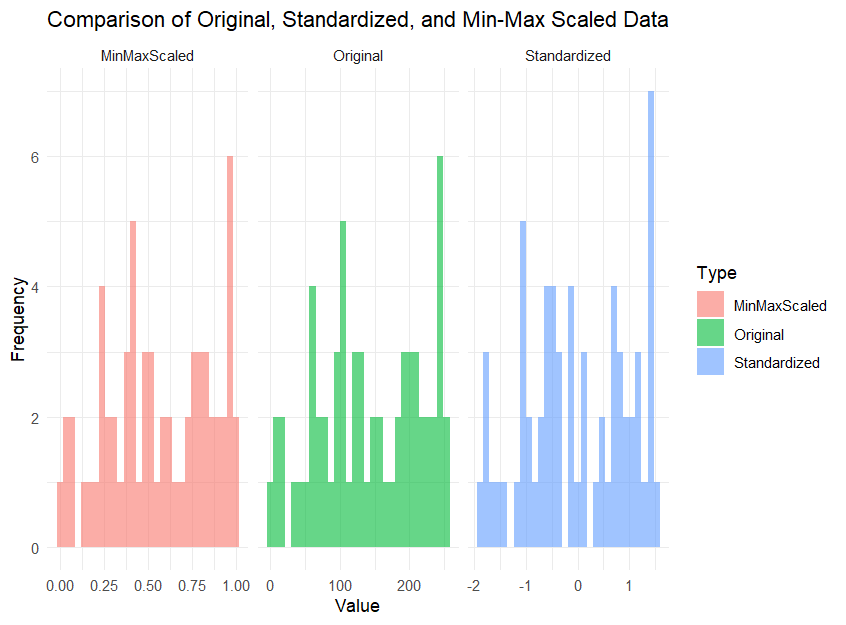
ggplot(df_long, aes(x = Value, fill = Type)) +
geom_histogram(alpha = 0.6, position = "identity", bins = 30) +
facet_wrap(~Type, scales = "free_x") + #패싯 : Type으로 분류하고 스케일을
#각 Type에 맡게 다시 스케일시키는 방식 : 'free_x'
theme_minimal() +
labs(title = "Comparison of Original, Standardized, and Min-Max Scaled Data", x = "Value", y = "Frequency")데이터 프레임 형태는 colnames = original,standardized,MinMaxScaled 이렇게 있고 이에 대한 수치형 데이터가 쫙 나열되어 있습니다. 이런 형태는 ggplot이 사용이 불가하기 때문에 한쪽 col에 original,standardized,MinMaxScaled을 몰아주고 수치형 데이터를 써야하는거죠. 아래와 같이 써야 합니다.
| Type(col) | Value(col) |
| original | 70 |
| standardized | 1.2 |
| MinMaxScaled | 0.8 |
| stanardized | -0.7 |
| original | 60 |
이러한 형태변환을 해주기 위해 tidyr 패키지에 있는 pivot_longer()함수를 사용해줍니다. 또는 melt()를 이용해주셔도 됩니다.
히스토그램은 y축이 빈도수라고 했기 때문에 이렇게 나타납니다. 코드에 대한 자세한 설명은 코드 주석을 참고해주세요.